Nimbus Parachain Consensus Framework¶
Introduction¶
Polkadot relies on a hybrid consensus model. In such a scheme, the block finality gadget and the block production mechanism are separate. Consequently, parachains only have to worry about producing blocks and rely on the relay chain to validate the state transitions.
At a parachain level, block producers are called collators. They maintain parachains (such as Moonbeam) by collecting transactions from users and offering blocks to the relay chain validators.
However, parachains might find the following problems they need to solve in a trustless and decentralized matter (if applicable):
- Amongst all of the nodes in the network, which ones are allowed to author blocks?
- If multiple nodes are allowed, will they be eligible at the same time? Only one? Maybe a few?
Enter Nimbus. Nimbus is a framework for building slot-based consensus algorithms on Cumulus-based parachains. It strives to provide standard implementations for the logistical parts of such consensus engines and helpful traits for implementing the elements (filters) that researchers and developers want to customize. These filters can be customizable to define what a block authorship slot is and can be composed, so block authorship is restricted to a subset of collators in multiple steps.
For example, Moonbeam uses a two-layer approach. The first layer comprises the parachain staking filter, which helps select an active collator pool among all collator candidates using a staked-based ranking. The second layer adds another filter which narrows down the number of collators to a subset for each slot.
Notice that Nimbus can only answer which collator(s) are eligible to produce a parachain block in the next available slot. It is the Cumulus consensus mechanism that marks this parachain block as best, and ultimately the BABE and GRANDPA hybrid consensus model (of the relay chain) that will include this parachain block in the relay chain and finalize it. Once any relay chain forks are resolved at a relay chain level, that parachain block is deterministically finalized.
The following two sections go over the filtering strategy currently used on Moonbeam.
Parachain Staking Filtering¶
Collators can join the candidate pool by simply bonding some tokens via an extrinsic. Once in the pool, token holders can add to the candidate's stake via delegation (also referred to as staking), that is, at a parachain level.
Parachain staking is the first of the two Nimbus filters applied to the candidate pool. It selects the top 12 candidates in terms of tokens staked in the network, which includes the candidate's bond and delegations from token holders. This filtered pool is called selected candidates, and selected candidates are renewed every round (which lasts 1200 blocks). For a given round, the following diagram describes the parachain staking filtering:
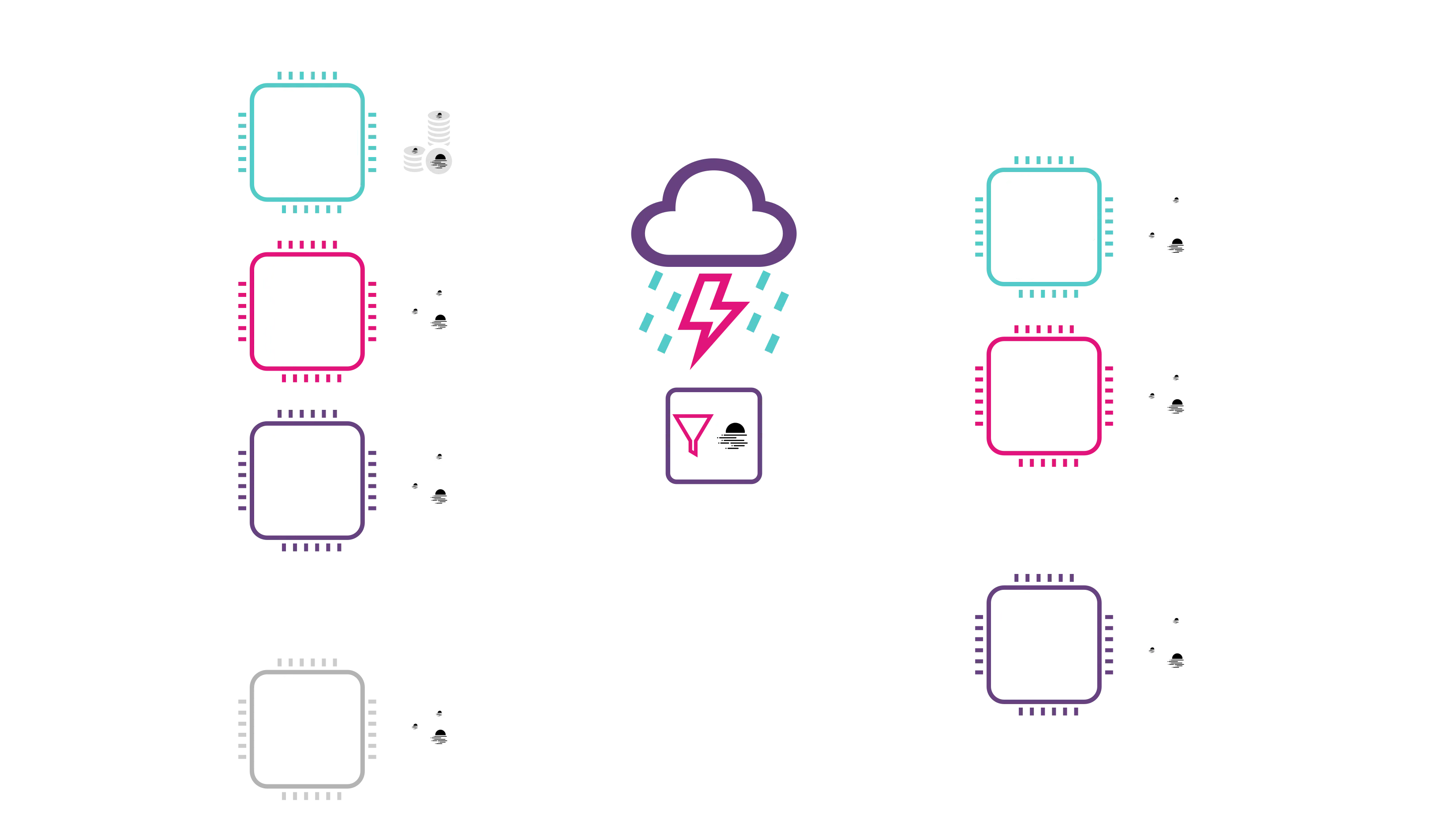
From this pool, another filter is applied to retrieve a subset of eligible candidates for the next block authoring slot.
If you want to learn more about staking, visit our staking documentation.
Fixed Size Subset Filtering¶
Once the parachain staking filter is applied and the selected candidates are retrieved, a second filter is applied on a block by block basis and helps narrow down the selected candidates to a smaller number of eligible collators for the next block authoring slot.
In broad terms, this second filter picks a pseudo-random subset of the previously selected candidates. The eligibility ratio, a tunable parameter, defines the size of this subset.
A high eligibility ratio results in fewer chances for the network to skip a block production slot, as more collators will be eligible to propose a block for a specific slot. However, only a certain number of validators are assigned to a parachain, meaning that most of these blocks will not be backed by a validator. For those that are, a higher number of backed blocks means that it might take longer for the relay chain to solve any possible forks and return a finalized block. Moreover, this might create an unfair advantage for certain collators that might be able to get their proposed block faster to relay chain validators, securing a higher portion of block rewards (if any).
A lower eligibility ratio might provide faster block finalization times and a fairer block production distribution amongst collators. However, if the eligible collators are not able to propose a block (for whatever reason), the network will skip a block, affecting its stability.
Once the size of the subset is defined, collators are randomly selected using a source of entropy. Currently, an internal coin-flipping algorithm is implemented, but this will later be migrated to use the relay chain's randomness beacon. Consequently, a new subset of eligible collators is selected for every relay chain block. For a given round and a given block XYZ, the following diagram describes the fixed-size subset filtering:
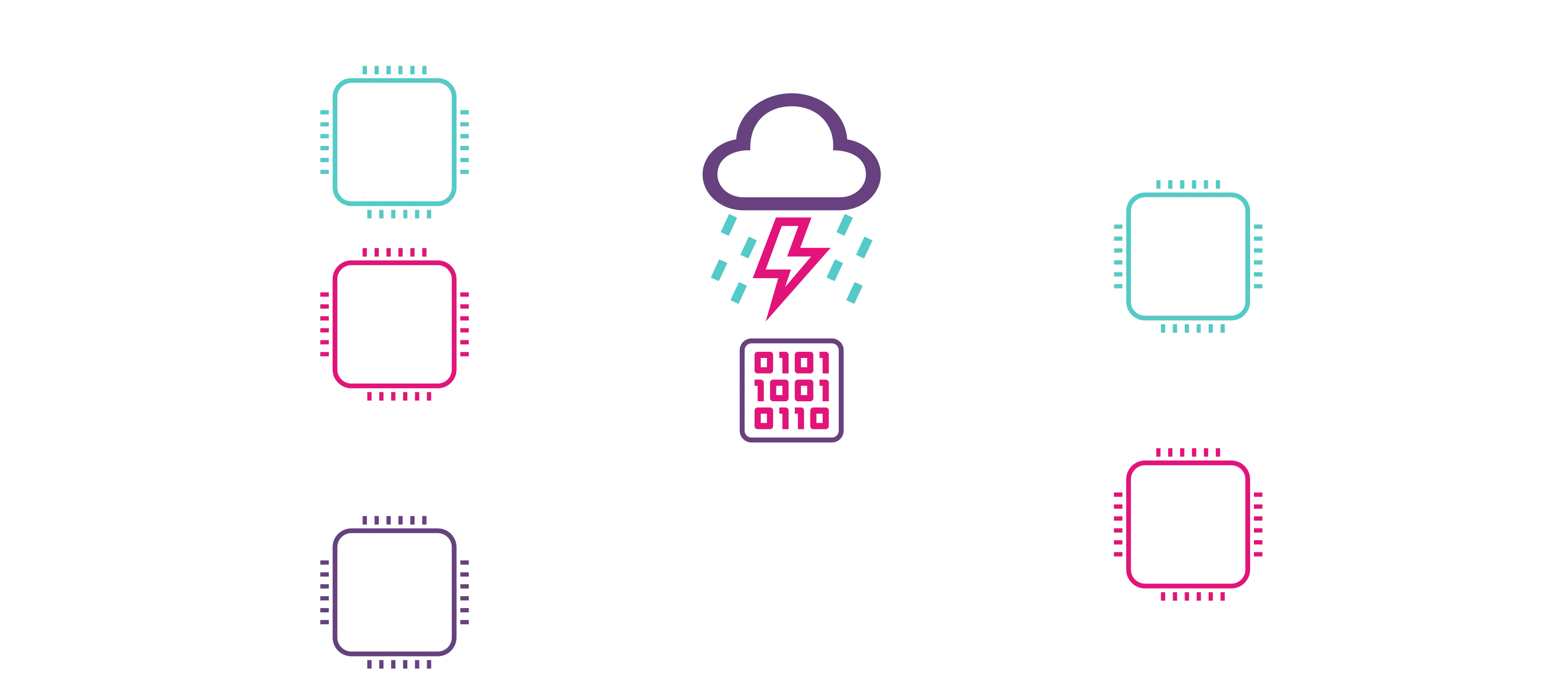
Why Nimbus?¶
You might ask yourself: but why Nimbus? Initially, it was not envisioned when Moonbeam was being developed. As Moonbeam progressed, the necessity for a more customizable but straightforward parachain consensus mechanism became clear, as the available methods presented some drawbacks or technical limitations.
With Nimbus, writing a parachain consensus engine is as easy as writing a pallet! This simplicity and flexibility is the main value it adds.
Some technical benefits of Nimbus are considered in the following sections.
Weight and Extra Execution¶
Nimbus puts the author-checking execution in a Substrate pallet. At first glance, you might think this adds a higher execution load to a single block compared to doing this check off-chain. But consider this from a validator’s perspective
The validators will also have to check the author. By putting the author-checking execution logic in a pallet, the execution time can be benchmarked and quantified with weights. If this execution time is not accounted for, there is the risk of a block exceeding the relay chain Wasm execution limit (currently 0.5 seconds).
In practice, this check will be fast and will most likely not push execution time over the limit. But from a theoretical perspective, accounting for its weight is better for implementation purposes.
Reusability¶
Another benefit of moving the author-checking execution to a pallet, rather than a custom executor, is that one single executor can be reused for any consensus that can be expressed in the Nimbus framework. That is slot-based, signature-sealed algorithms.
For example, the relay-chain provided consensus, AuRa and BABE each have their own custom executor. With Nimbus, these consensus mechanisms can reuse the same executor. The power of reusability is evidenced by the Nimbus implementation of AuRa in less than 100 lines of code.
Hot-Swapping Consensus¶
Teams building parachains may want to change, tune, or adjust their consensus algorithm from time to time. Without nimbus, swapping consensus would require a client upgrade and hard fork.
With the Nimbus framework, writing a consensus engine is as easy as writing a Substrate pallet. Consequently, swapping consensus is as easy as upgrading a pallet.
Nonetheless, hot swapping is still bounded by consensus engines (filters) that fit within Nimbus, but it might be helpful for teams that are yet confident on what consensus they want to implement in the long run.
| Created: May 24, 2021